در این مطلب، میبینیم که EFK چیست و یک راهنمای جامع نصب و راهاندازی بخشهای مختلف آن را بررسی کنیم. EFK یک استک در کوبرنتیز است که برای آنالیز گزارشها و مانیتور کردن دادهها استفاده میشود. اگر از کوبرنتیز استفاده میکنید، مهم است که نحوه راهاندازی این stack مهم و کاربردی را بررسی کنید و با جزئیات آن آشنا شوید. در ادامه این آموزش از بلاگ ابر زس، Fluentd ،Elasticsearch و Kibana را در کوبرنتیز دیپلوی (deploy) کرده و نحوه کار با آن را بررسی میکنیم و به طور دقیقتر میبینیم که EFK چیست و چه کاری انجام میدهد.
پیش از ادامه مطلب، در صورتیکه مایل هستید بدانید در مورد کوبرنتیز بیشتر بدانید، پیشنهاد میکنیم مطلب «کوبرنتیز چیست؟» را مطالعه نمایید.
EFK چیست؟
قبل از آن که به بررسی مراحل و روش نصب استک EFK در کوبرنتیز بپردازیم، بیایید ببینیم که EFK چیست و چه کاربردی دارد. استک (Stack) EFK یکی از بهترین و البته محبوبترین روشهای جمعآوری و آنالیز گزارش در کوبرنتیز (Kubernetes) به شمار میرود که بهصورت متنباز طراحی شده است. EFK مخفف سه عبارت Fluentd ،Elasticsearch و Kibana است که در ادامه بیشتر درباره هریک توضیح میدهیم.
- الستیک سرچ (Elasticsearch)
برای جدا کردن دادههای گزارش در حجمهای زیاد، از موتور جستجوی توزیع شده و مقیاسپذیر Elasticsearch استفاده میکنند. الستیک سرچ همچنین یک دیتابیس مبتنی بر موتور جستجوی Lucene به شمار میرود که وظیفه اصلی آن، ذخیره و بازیابی لاگهای دریافتی از fluentd است. علاوه بر این Elasticsearch توسط بسیاری از سازمانها استفاده میشود و به حل مشکل جدا کردن حجم بالایی از دادههای بدون ساختار، کمک میکند. معمولاً Elasticsearch و Kibana در کنار هم استفاده و مستقر میشوند.
- فلوئنتدی (fluentd)
فلوئنتدی مسئول جمعآوری گزارش است که از چندین منبع داده و فرمتهای خروجی مختلف پشتیبانی میکند و بهصورت متنباز طراحی شده است. فلوئنتد بهعنوان یک ارسال کننده لاگ، میتواند گزارشها را به راهکارهایی مانند Stackdriver Cloudwatch ،elasticsearch ،Splunk ،Bigquery و … ارسال کند. بهعبارتدیگر، fluentd یک لایه اتصال بین سیستمهای تولیدکننده گزارش و سیستمهای ذخیره دادههای گزارش، ایجاد میکند. نکته مهمی که باید به آن توجه کنید، این است که در کوبرنتیز، Fluentd به دلیل امکان تجزیه لاگهای کانتینر بدون هیچگونه تنظیمات اضافی، از بهترین انتخابها است.
- کیبانا (Kibana)
کیبانا یک query engine برای کاوش کردن دادههای گزارش ازطریق رابط وب، ایجاد تصاویر برای گزارش ایونتها و همچنین کوئری فیلتر کردن اطلاعات برای شناسایی مشکلات خاص است. با استفاده از Kibana میتوانید هر نوع داشبوردی را به طور مجازی بسازید. از KQL (مخفف Kibana Query Language) برای کوئری دادههای elasticsearch استفاده میشود، اما در اینجا، از Kibana برای کوئری دادههای ایندکس شده در elasticsearch استفاده میشود. بهطورکلی، Kibana ابزاری گرافیکی برای کوئری، نمایش دادهها و نیز داشبوردها است.
معماری EFK چیست؟
با بررسی نمودار زیر، میتوانید ببینید که ساختار معماری EFK چیست و اجزای مختلف آن چطور کار میکنند. همانطور که قبل از این گفتیم، استک EFK از سه جزء تشکیل شده که در معماری آن، هر سه نقش خاص خود را دارند.
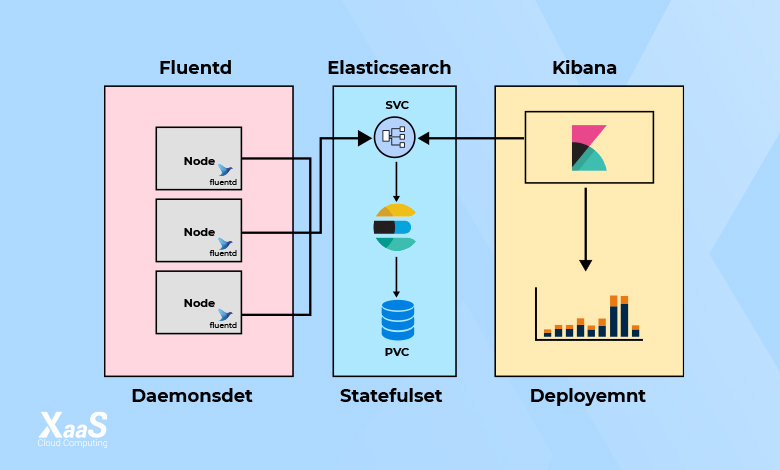
معماری و دیپلویمنت اجزای EFK بهصورت زیر است:
- Fluentd: بهعنوان daemonset برای جمعآوری لاگهای کانتینر از تمام گرهها، مستقر میشود. همچنین به نقطه پایانی (endpoint) در Elasticsearch متصل میشود تا گزارشها را ارسال کند.
- Elasticsearch: بهعنوان statefulset مستقر شده و دادههای گزارش را نگهداری میکند. همچنین نقطه پایانی Elasticsearch در معرض دید قرار میگیرد تا Fluentd و kibana به آن متصل شوند.
- Kibana: بهعنوان deployment مستقر شده و به نقطه پایانی سرویس elasticsearch متصل میشود.
حالا که میدانیم ساختار کلی EFK چیست و چه اتصالاتی انجام میشود، میتوانیم نحوه استقرار اجزای مختلف آن را بررسی کنیم.
نحوه استقرار Elasticsearch Stateful
استقرار جزء Elasticsearch بهعنوان یک Statefulset انجام شده و چندین رپلیکا با استفاده از یک سرویس headless به هم متصل میشوند. سرویس headless svc به پادهای دامنه DNS کمک میکند. مانیفست زیر را با عنوان es-svc.yaml ذخیره کنید.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-nodeحالا میتوانیم آن را بسازیم.
kubectl create -f es-svc.yamlقبل از شروع ایجاد statefulset برای elasticsearch، لازم است یادآوری کنیم که statefulset به یک کلاس ذخیرهسازی ازقبل تعریفشده نیاز دارد که با استفاده از آن بتوان در هر زمان، Volumeهای موردنیاز را ایجاد کرد. در این مرحله میتوانیم Elasticsearch statefulset را ایجاد کنیم. برای این کار، مانیفست زیر را با عنوان es-svc.yaml ذخیره کنید.
نکتهای که باید به آن توجه کنید، این است که statefulset، در فرایند نصب، PVC را با حجم ذخیرهسازی پیشفرض کلاس انجام میدهد. اگر به کلاس ذخیرهسازی سفارشی برای PVC نیاز دارید، میتوانید آن را در volumeClaimTemplates با از کامنت خارج کردن پارامتر storageClassName اضافه کنید.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
# storageClassName: ""
resources:
requests:
storage: 3Giحالا میتوانید statefulset را ایجاد کنید.
kubectl create -f es-sts.yamlبررسی دیپلویمنت Elasticsearch
حالا که میدانیم روش استقرار جزء Elastisearch در EFK چیست و مراحل آن را انجام دادیم، پس از اجرای پادهای Elastisearch میتوانیم دیپلویمنت Elasticsearch statefulset را تأیید کنیم. سادهترین روش برای این کار، آن است که وضعیت کلاستر را بررسی کنیم. برای بررسی وضعیت، پورت ۹۲۰۰ در Elasticsearch pod را باید port-forward کنید.
kubectl port-forward es-cluster-0 9200:9200برای بررسی وضعیت سلامت کلاستر Elastisearch، دستور زیر را در ترمینال اجرا کنید.
curl http://localhost:9200/_cluster/health/?prettyخروجی نهایی، وضعیت کلاستر Elasticsearch را نشان میدهد. درصورتیکه همه مراحل را بهدرستی طی کرده باشید، در اسکریپت زیر میبینید که قسمت استاتوس (status) عبارت green را نشان میدهد.
{
"cluster_name" : "k8s-logs",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 8,
"active_shards" : 16,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}نحوه استقرار Kibana
برای بررسی این که روش نصب EFK چیست و نحوه دیپلویمنت اجزای مختلف آن، لازم است تا استقرار Kibana را هم بررسی کنیم. میتوان بهعنوان یک دیپلویمنت ساده کوبرنیتز، Kibana را ایجاد کرد. همانطور که در معماری EFK بررسی کردیم، استقرار Kibana به elasticsearch همبستگی دارد. روند انجام این کار به این صورت است که از URL نقطه پایانی برای اتصال به elasticsearch استفاده میکند. در مانیفست زیر هم میتوانید ببینید که یک env var ELASTICSEARCH_URL برای پیکربندی نقطه پایان کلاستر Elasticsearch تعریف شده است. ایجاد دیپلویمنت کیبانا با عنوان مانیفست kibana-deployment.yaml انجام میشود.
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.5.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601حالا میتوان مانیفست را ایجاد کرد.
kubectl create -f kibana-deployment.yamlمیتوانیم برای دسترسی رابط کاربری Kibana ازطریق آدرس IP، یک سرویس از نوع NodePort ایجاد کنیم. اگرچه ما از nodeport برای اهداف نمایشی استفاده میکنیم، اما در حالت ایدهال، ورودی به کوبرنتیز با یک سرویس ClusterIP برای پیادهسازی واقعی پروژه انجام میشود. برای این کار، مانیفست زیر را با عنوان kibana-svc.yaml ذخیره کنید.
apiVersion: v1
kind: Service
metadata:
name: kibana-np
spec:
selector:
app: kibana
type: NodePort
ports:
- port: 8080
targetPort: 5601
nodePort: 30000حالا kibana-svcرا ایجاد کنید.
kubectl create -f kibana-svc.yamlحالا میتوانید ازطریق http://<node-ip>:3000به Kibana دسترسی داشته باشید.
نحوه تأیید دیپلویمنت Kibana
پس از آن که پادها به حالت اجرا شده در آمدند، میتوانید استقرار این جزء از EFK را تأیید کنید. برای این کار، راحتترین روش این است که از طریق دسترسی به رابط کاربری در کلاستر اقدام کنید. بیایید ببینیم روش تأیید استقرار این بخش از EFK چیست و چطور انجام میشود.
برای بررسی وضعیت، باید پورت شماره ۵۶۰۱ پاد کیبانا را فوروارد کنید. اگر سرویس nodePort را ایجاد کرده باشید، میتوانید از آن هم استفاده کنید.
kubectl port-forward <kibana-pod-name> 5601:5601پس از آن، میتوانید ازطریق مرورگر وب به رابط کاربری دسترسی پیدا کرده و یا با استفاده از curl یک درخواست ایجاد کنید.
curl http://localhost:5601/app/kibanaپس از انجام این مراحل، چنانچه رابط کاربری Kibana بارگیری شده و یا یک پاسخ معتبر curl دریافت کنید، میتوان گفت که اجرای Kibana بهدرستی انجام شده است.
نحوه استقرار مانیفستهای Fluentd کوبرنتیز
از آنجاییکه فلوئنتدی جریانهای داده را از تمامی نودهای در کلاسترها دریافت میکند، به عنوان یک daemonset دیپلوی شده است. همچنین Fluentd برای فهرست کردن و استخراج متادیتاهای پادها، در تمام namespaceها، به مجوزهای خاصی نیاز دارد.
Kubernetes Service accounts در کنار نقشهای کلاستر، برای فراهم کردن سطوح دسترسی به کامپوننتها در کوبرنتیز به کار میرود. بیایید ببینیم که روش ایجاد اکانت سرویس مورد نیاز و نقشها در این بخش از EFK چیست.
ایجاد Fluentd Cluster Role
یک Cluster Role در کوبرنتیز، شامل قوانینی است که مجموعهای از مجوزها را نشان میدهد. در ادامه، میخواهیم برای پادها و namespaceها در Fluentd مجوزهایی را ایجاد کنیم. برای این کار، باید یک مانیفست fluentd-role.yaml ایجاد کنید.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watchبرای اعمال مانیفست، از اسکریپت زیر استفاده میکنیم.
kubectl create -f fluentd-role.yamlایجاد حساب کاربری Fluentd Service
در این بخش، میخواهیم یک Fluentd service account ایجاد کنیم. اما service account در EFK چیست و چه وظیفهای دارد. service account در کوبرنتیز، به یک پاد هویت میدهد. برای ایجاد یک حساب کاربری که با پادهای Fluentd استفاده میشود، ابتدا یک مانیفست fluentd-sa.yaml ایجاد کنید.
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
labels:
app: fluentdاعمال کردن مانیفست ازطریق اسکریپت زیر انجام میشود.
kubectl create -f fluentd-sa.yamlایجاد Fluentd Cluster Role Binding
در کوبرنتیز، یک Cluster rolebinding مجوزهای تعریف شده در نقش کلاستری را به یک Service Account میدهد. در این بخش، میخواهیم تا بین service account ساخته شده در مرحله بالا و Role، یک Rolebinding ایجاد کنیم. برای این کار، یک مانیفست fluentd-rb.yaml ایجاد میکنیم.
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: defaultبرای اعمال مانیفست، از دستور زیر استفاده میکنیم.
kubectl create -f fluentd-rb.yamlنحوه استقرار Fluentd DaemonSet
در این مرحله، بیایید ببینیم که نحوه دیپلویمنت daemonset در EFK چیست. برای این کار، ابتدا اسکریپت زیر را با عنوان fluentd-ds.yaml ذخیره کنید.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containersحالا مانیفست Fluentd را اعمال میکنیم.
kubectl create -f fluentd-ds.yamlنحوه تأیید نصب Fluentd
حالا که میدانیم مراحل و روش استقرار Fluentd در EFK چیست و بخشهای مختلف آن را بررسی کردیم، وقت آن است تا روند نصب آن را تأیید کنیم. برای این کار، باید یک پاد را راهاندازی کنید که به طور مداوم، لاگ ایجاد میکند. پس از ایجاد لاگها، سعی میکنیم آنها را در Kibana ببینیم. برای این کار، اسکریپت زیر را با عنوان test-pod.yaml ذخیره کنید.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,'i=0; while true; do echo "Thanks for visiting devopscube! $i"; i=$((i+1)); sleep 1; done']سپس مانیفست را اعمال میکنیم.
kubectl create -f test-pod.yamlدر این مرحله، باید به Kibana رفته و بررسی کنیم که آیا لاگهای مربوط به این پاد که توسط Fluentd جمعآوری شده، در elasticsearch ذخیره میشوند یا خیر. برای این منظور، باید مراحل زیر را به طور دقیق دنبال کنید:
مرحله اول: باز کردن رابط کاربری kibana
در مرحله اول، باید با استفاده از پروکسی یا نقطه پایانی سرویس nodeport، رابط کاربری کیابانا را باز کنید. سپس به کنسول مدیریت آن بروید.
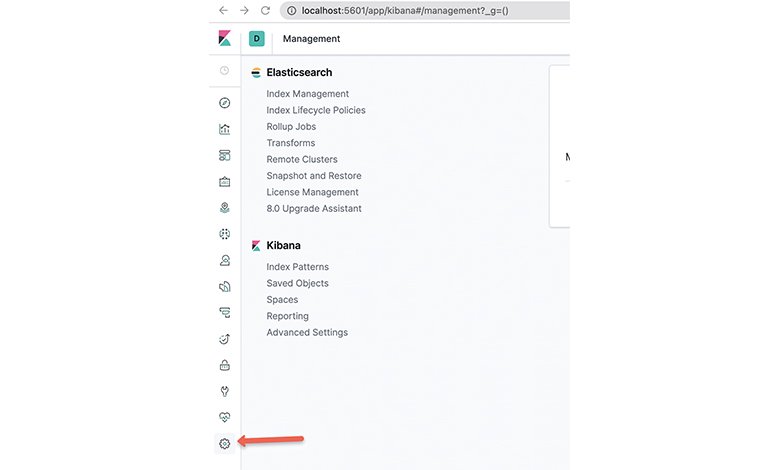
مرحله دوم: بخش Index Pattern
در این مرحله، گزینه Index Pattern را در زیر بخش مربوط به Kibana انتخاب کنید.
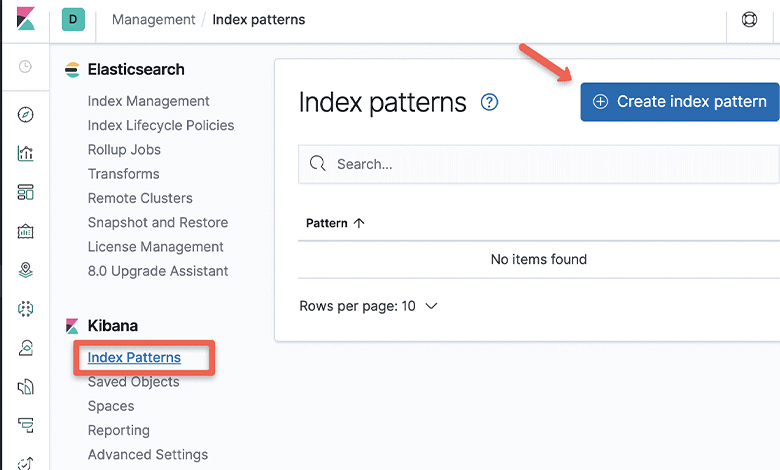
مرحله سوم: ایجاد Index Pattern
با استفاده از ورود دستور زیر در باکس مربوطه، یک Index Pattern جدید ایجاد کنید.
logstash-*
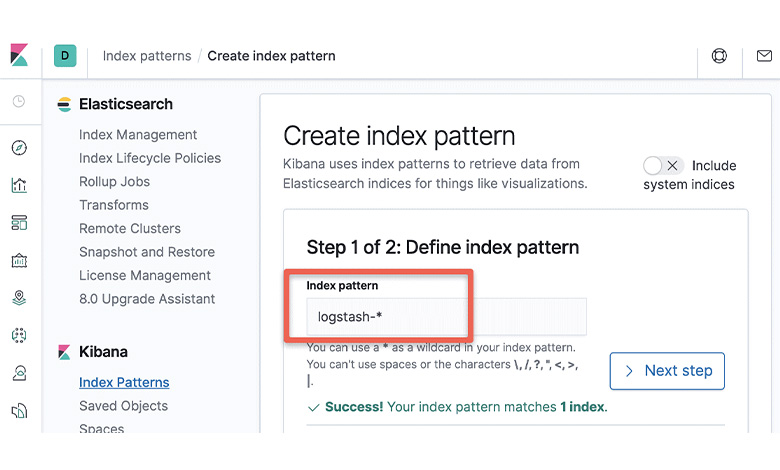
مرحله چهارم: انتخاب timestamp
در timestamp، گزینه “@timestamp” را انتخاب کنید.
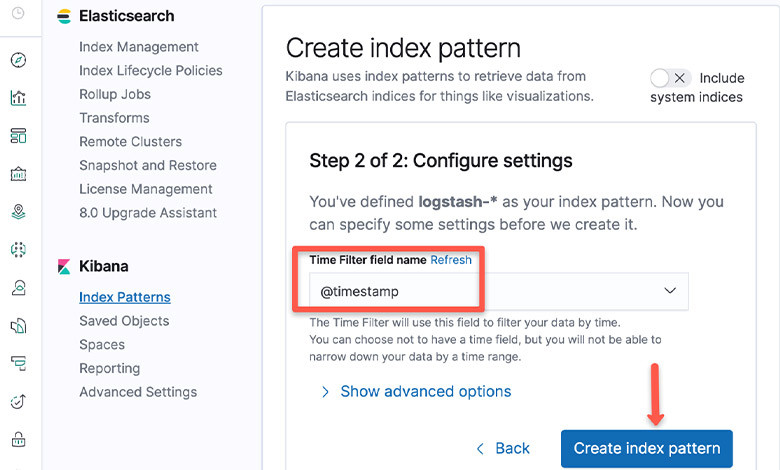
مرحله پنجم: اتمام ایجاد index pattern و امکان بررسی کنسول
در این مرحله، ایجاد index pattern به پایان رسیده و میتوانید کنسول را بررسی کنید. در کنسول میتوانید تمام گزارشهای صادرشده بهوسیله fluentd، مانند گزارشهای مربوط به پاد آزمایشی که ایجاد کردیم را بررسی کنید.
جمعبندی
در این مطلب به طور کامل دیدیم که EFK چیست و نحوه راهاندازی زیرساخت ورود به سیستم را در کوبرنتیز بررسی کردیم. EFK مخفف سه
عبارت Fluentd ،Elasticsearch و Kibana است که هریک نحوه استقرار و دیپلویمنت خاص خود را دارند. اگر از کوبرنتیز استفاده میکنید، آشنایی با جزئیات EFK بسیار مهم خواهد بود.
در صورتیکه مایل هستید استک ELK روی سرویس ابری راهاندازی شود، ابر زَس تحت «سرویس مدیریت شده»، ELK را برای شما طراحی و اجرا کرده و در اختیارتان قرار میدهد.