ELK چیست؟ + راهنمای نصب ELK روی اوبونتو
دلیل محبوبیت ELK چیست؟ این پلتفرم چه قابلیتها و امکاناتی ارائه میدهد که باعث شده تا این اندازه محبوب باشد؟ روند کار اجزای مختلف ELK Stack به چه صورت است؟ در این مقاله از بلاگ ابر زس قصد داریم به این سوالات پاسخ دهیم.
بهطورکلی، ELK یک پلتفرم تشکیل شده از سه پروژه محبوب برای جمعآوری گزارشها و تجزیهوتحلیل آنها است و با مانیتورینگ برنامهها و زیرساختها، درک کلی درباره عیبیابی سریعتر و آنالیز امنیتی دادهها و… را ارائه میدهد. در ادامه بیشتر بررسی میکنیم که ELK چیست و چطور کار میکند.
ELK چیست؟
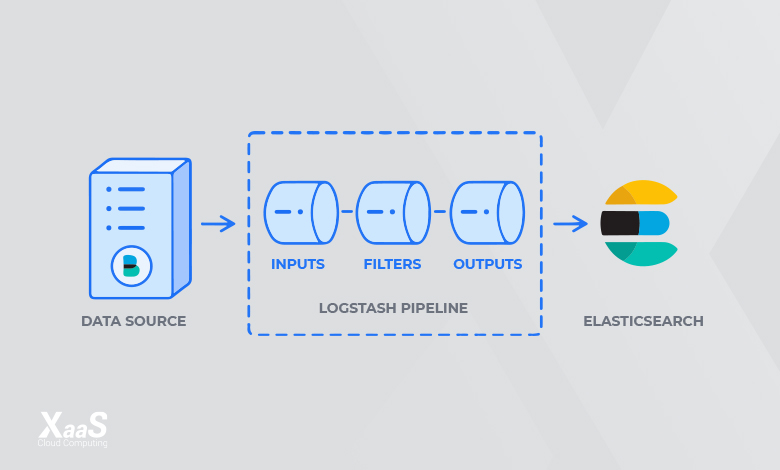
قبل از آن که به بررسی نحوه عملکرد استک ELK بپردازیم، بهتر است ببینیم که ELK چیست و شامل چه چیزهایی است. ELK یک استک تشکیل شده از سه پروژه محبوب شامل Logstash ،Elasticsearch و Kibana است. این مجموعه در کنار هم امکان جمعآوری گزارشها (Logs) از تمام سیستمها، زیرساختها و اپلیکیشنها را فراهم میکند و میتوانید با تجزیهوتحلیل این گزارشها و مانیتور کردن آنها، روند عیبیابی سریعتری داشته باشید و فرایند آنالیز را با امنیت بالا انجام دهید. یکی از کاربردهای مهم استک ELK، استفاده سازمانها از آن برای جمعآوری و تحلیل گزارشهای سرویس ابری است.
البته این پروژه تنها به این سه جزء محدود نشده و اضافه شدن یک پروژه دیگر تحت عنوان Beats، آن را تکمیل میکند. بیایید بیشتر با اجزای ELK آشنا شویم.
الاستیک سرچ (E = Elasticsearch)
اولین جزء از استک ELK، پروژه Elasticsearch است. الاستیک سرچ بهعنوان یک موتور جستجو و آنالیتیک توزیع شده و مبتنی بر آپاچی لوسن (Apache Lucene) طراحی شده است. دلایلی همچون قدرت بالای کارایی، پشتیبانی از زبانهای مختلف و فایلهای JSON بهصورت schema-free، باعث شده تا Elasticsearch به انتخابی عالی و ایدهآل برای آنالیز گزارشهای مختلف و کاربردهای جستجو تبدیل شود.
لاگاستش (L = Logstash)
همانطور که در ELK چیست توضیح دادیم، جزء بعدی این استک را پروژه Logstash تشکیل میدهد. Logstash ابزاری است که بهصورت منبعباز طراحی شده و به شما این امکان را میدهد تا پس از جمعآوری و دریافت دادهها، در آنها تغییراتی ایجاد کنید و سپس دادهها را به مقصد ارسال کند.
یکی از ویژگیهای مهم این ابزار آن است که با داشتن فیلترهای پیشفرض و پشتیبانی از بیش از ۲۰۰ پلاگین، میتوان هر نوع داده را از هر منبعی دریافت کرد. میتوان Logstash را با Elasticsearch ادغام کرده و بهعنوان یک پایپلاین (pipeline)، برای فهرست کردن دادهها از آن استفاده کرد. از ویژگیهای مهم این ابزار میتوان به موارد زیر اشاره کرد:
- بارگیری راحت دادههای ساختاریافته
- ارائه فیلترهای ازپیشساختهشده
- معماری پلاگین انعطافپذیر
کیبانا (K = Kibana)
جزء سومی که در پروژه ELK شرکت دارد، ابزار Kibana است. کیبانا ابزاری برای نمایش (Visualization) و کاوش (Exploration) در دادهها است که از آن برای تحلیلهای مبتنی بر زمان و رویدادها و مانیتورینگ اپلیکیشنها استفاده میشود. از قابلیتهای مهم این ابزار میتوان به مواردی مانند هیستوگرام، نمودار خطی، نمودار دایرهای، نقشههای حرارتی و پشتیبانی جغرافیایی اشاره کرد. علاوه بر این، Kibana با Elasticsearch ادغام شده و به همین دلیل، به یک گزینه عالی برای نمایش دادههای ذخیرهشده تبدیل شده است.
حالا میدانیم اجزای اصلی در پروژه ELK چیست و هریک چهکارهایی را میتوانند انجام دهند. این اجزای مختلف با هم همکاری کرده و در کنار یکدیگر، برای مانیتورینگ، عیبیابی و ایمنسازی محیطهای IT استفاده میشوند. البته کاربردهای گسترده دیگری ازجمله هوش تجاری (Business intelligence) و آنالیز وب (Web Analytics) هم برای استک ELK وجود دارد. اگر بخواهیم روند کار در این مجموعه را بررسی کنیم، میتوان گفت که Beats و Logstash به جمعآوری و پردازش دادهها کمک کرده و سپس Elasticsearch این دادهها را فهرستبندی و ذخیره میکند تا درنهایت، Kibana یک رابط کاربری برای جستجوی دادهها فراهم کند.
نحوه عملکرد استک ELK
همانطور که میدانید، از ELK برای رفع بخش قابلتوجهی از مشکلات مانند آنالیز گزارشها، جستجوی اسناد، اطلاعات امنیتی و مدیریت رویدادها استفاده میشود. اما سؤال اصلی اینجاست که روش عملکردی ELK چیست و این ابزار عملکردها، را به چه صورتی اجرا میکند. پیشازاین، دیدیم که ELK از سه جزء اصلی تشکیل شده است که هریک وظایف خاص خود را دارند. عملکرد زنجیرهوار این اجزا، فرایند اجرای قابلیتهای ELK را ممکن میکند. این شیوه عملکردی، بهصورت زیر است:
- دادهها توسط Logstash جمعآوری و پردازش شده، سپس تبدیل شده و به مقصد مناسب فرستاده میشود.
- Elasticsearch دادههای دریافت شده را فهرستبندی کرده و سپس با آنالیز و جستجوی آنها، به Kibana انتقال میدهد.
- درنهایت عملکرد visualize نتایج حاصل از آنالیز، توسط کیبانا اجرا میشود.
مزایا و معایب ELK Stack
اکنون که با مفهوم استک ELK چیست آشنا شدیم، در این بخش به بررسی مزایا و معایب آن میپردازیم.
مزایای ELK چیست؟
- رایگان است: قیمت ارزان ELK یکی از مزیتهای آن بهشمار میرود. همه اجزای نرمافزار ELK متنباز و رایگان هستند، بنابراین هیچ خرید اولیه برای مجوز نرمافزار ضروری نیست.
- انتخابهای میزبانی متعدد: سازمانها میتوانند هنگام ایجاد یک استک ELK، از میان گزینههای میزبانی مختلف انتخاب کنند. برای مثال میتوان با استفاده از یک سرور اختصاصی یا با خرید سرور کلود استقرار و راهاندازی یک استک ELK را اجرا کرد.
- قابلیتهای لاگ یکپارچه: قابلیت لاگ متمرکز ELK از مهمترین ویژگیهای آن به شمار میرود. این قابلیت به کاربران امکان میدهد که دادههای لاگها را از محیطهای پیچیده ابری، تحت یک فهرست قابل جستجو یکپارچه کنند.
- نمایش و تحلیل داده آنی: کاربران استک ELK میتوانند از Kibana برای ساخت داشبوردهای سفارشی و تجسم دادهها با استفاده از دادههای آنی Elasticsearch استفاده کنند.
- کلاینت رسمی در چندین زبان برنامهنویسی: برخی از کاربران استک ELK از چندین زبان برنامهنویسی در کدبیس خود استفاده میکنند. استک ELK از حداقل ۱۰ زبان برنامهنویسی شامل جاوا اسکریپت، گو، پایتون، داتنت و پِرل، پشتیبانی میکند و برای این زبانها، نسخه کلاینت رسمی ارائه کرده است. علاوه بر این، جامعه اوپن سورس الاستیک سرچ، نسخههای کلاینت برای زبانهای دیگر را هم ارائه میکنند.
معایب ELK چیست؟
- مدیریت پیچیده: استک ELK برای دانلود رایگان در دسترس است و هزاران نفر هر ماه آن را دانلود می کنند، با این حال، دریافت نرمافزار تنها بخش ساده آن است. نصب یک استک شامل روشهای پیچیده چند مرحلهای میشود. همچنین سازمانها برای نگهداری از ELK نیاز به نیروهای آشنا با این پروژه یا آموزش نیروهای خود دارند.
- هزینههای مالکیت بالا: اگرچه استفاده از نرمافزار استک ELK رایگان است، اما نیاز به زیرساختها و منابع برای ساخت، گسترش و نگهداری دارد.
- مشکلات پایداری و آپتایم: برخی از کاربران استک ELK مشکلات پایداری و آپتایم را گزارش کردهاند که با افزایش حجم دادهها پیش میآید.
- دوراهی انتخاب بین حفظ داده یا هزینه: با افزایش حجم دادهها، کاربران استک ELK با این چالش مواجه میشوند که بین «نگهداری دادهها» یا «هزینه» کدامیک را انتخاب کنند.
- چالشهای مقیاسبندی: تمامی معایبی که در بالا اشاره کردیم، به چالشهای مقیاسپذیری استک ELK دامن میزند. البته چنین موضوعی به این معنی نیست که استک ELK قابلیت مقیاسپذیری ندارد اما در مقایسه با سایر راهکارهای جایگزین، کاربران را با چالشهای بیشتری مواجه میکند.
دلایل محبوبیت ELK چیست؟
باوجود قابلیتها و گستردگی امکانات این ابزار، احتمالاً بهراحتی بتوان حدس زد که دلیل محبوبیت ELK چیست و چرا استفاده از آن بیشتر شده است. بهطورکلی، ELK به دلیل برآورده کردن نیاز مدیریت گزارشها و آنالیتیک، اهمیت پیدا میکند. امروزه مانیتورینگ و نظارت روی اپلیکیشنهای مدرن و زیرساختهای IT آنها، به یک شیوه مدیریت همهجانبه برای گزارشها و آنالیز دادهها نیاز دارد. این مسئله، مهندسان را با چالشهای متعددی روبرو میکند.
ELK با ارائه یک پلتفرم جامع و قدرتمند امکان جمعآوری و پردازش دادهها و ذخیره دادهها در یک مکان با امکان مقیاسبندی در صورت رشد دادهها را فراهم میکند و همچنین مجموعهای کامل از ابزارهای تجزیهوتحلیل داده را ارائه میدهد.
همانطور که قبل از این با بررسی ELK چیست توضیح دادیم، این ابزار بهصورت منبعباز طراحی شده و این یکی از دلایل دیگر محبوبیت ELK است. Open Source بودن یک نرمافزار، دسترسی گستردهتری را برای آن فراهم میکند و امکان استفاده از ویژگیها و نوآوریهای جدید را ارائه میدهد تا در صورت نیاز، بتوان ابزار موردنظر را متناسب با نیاز، مقیاسبندی کرد.
بهطورکلی، استک ELK نیازهای متناسب با فضای تجزیهوتحلیل گزارش (Log) را برآورده و با انتقال بیشتر زیرساختهای IT به فضای ابری، امکان نظارت و پردازش گزارشهای سرور را فراهم میکند. ELK یک ابزار ساده و درعینحال قوی برای تجزیهوتحلیل گزارش توسط توسعهدهندگان و مهندسان DevOps فراهم میکند تا درک بهتری از دلایل اختلال در سیستم، عملکرد برنامه و نظارت بر زیرساخت را با هزینه کمتر، به دست آورند.
نصب ELK روی اوبونتو
برای نصب ELK شما به موارد زیر نیاز دارید:
سرور اوبونتو ۲۲.۰۴ با ۴ گیگابایت رم و ۲ پردازنده که با یک کاربر non-root sudo تنظیم شده است.
نکته مهم: به این موضوع توجه داشته باشید، ازآنجاییکه Elastic Stack برای دسترسی به اطلاعات مهمی درباره سرور شما استفاده میشود و نمیخواهید کاربران غیرمجاز به آنها دسترسی داشته باشند، پس حتما برای امنیت سرور خود یک گواهی TLS/SSL نصب کنید.
مرحله اول: نصب و پیکربندی Elasticsearch
در اجزای Elasticsearch بهصورت پیشفرض در پکیج ریپازیتوری دردسترس نیستند.. با این حال، میتوان آنها را پس از افزودن فهرست منبع پکیج الاستیک با APT نصب کرد.
همه پکیجها با کلید امضای الاستیک سرچ امضا شدهاند تا از سیستم شما در برابر جعل پکیج محافظت کنند. پکیجهایی که با استفاده از کلید احراز هویت شدهاند، توسط Package Manager قابل اعتماد شناخته میشوند. در این مرحله، کلید عمومی GPG Elasticsearch را وارد کنید. سپس لیست منبع بسته Elastic را برای نصب Elasticsearch اضافه میکنید.
برای شروع، از cURL (یک ابزار خط فرمان برای انتقال دادهها با URLها) برای انتقال دادهها با URL به منظور ورود کلید GPG عمومی الاستیک سرچ به APT استفاده کنید. توجه داشته باشید که ما از آرگومانهای fsSL- استفاده میکنیم تا همه پیشرفتها و خطاهای احتمالی را خاموش کنیم (بهجز خرابی سرور) و به cURL اجازه میدهیم در صورت تغییر مسیر، در یک مکان جدید درخواست ارسال کند. خروجی کامند curl را به دستور gpg --dearmor وارد کنید که کلید را به فرمتی تبدیل میکند تا apt بتواند از آن برای تأیید پکیجهای دانلود شده استفاده کند.
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch |sudo gpg --dearmor -o /usr/share/keyrings/elastic.gpg
در مرحله بعد، لیست منبع Elastic را به فهرست sources.list.d اضافه کنید، جایی که APT منابع جدید را جستجو میکند:
echo "deb [signed-by=/usr/share/keyrings/elastic.gpg] https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
بخش [signed-by=/usr/share/keyrings/elastic.gpg] فایل به apt دستور میدهد تا از کلیدی که دانلود کردهاید برای تأیید اطلاعات ریپازیتوری و فایل پکیجهای الاستیک سرچ استفاده کند. اکنون با استفاده از دستور زیر فهرست پکیج خود را بهروزرسانی کنید تا APT منبع جدید Elastic را بخواند:
sudo apt update
سپس Elasticsearch را با این دستور نصب کنید:
sudo apt install elasticsearch
الاستیک سرچ اکنون نصب شده و آماده پیکربندی است. از text editor دلخواه خود برای ویرایش فایل پیکربندی اصلی elasticsearch.ymlاستفاده کنید. ما در این مقاله از nano استفاده میکنیم:
sudo nano /etc/elasticsearch/elasticsearch.yml
نکته: به این موضوع دقت کنید که فایل پیکربندی الاستیک سرچ در قالب YAML است؛ به این معنی که ما باید فرمت تورفتگی (indentation) را حفظ کنیم. اطمینان حاصل کنید که هنگام ویرایش این فایل، هیچ فاصله اضافی اضافه نکنید.
فایل elasticsearch.yml گزینههای پیکربندی را برای کلاستر، نود، مسیرها، حافظه، شبکه، کشف و gateway فراهم میکند. اکثر این گزینهها در فایل از قبل پیکربندی شدهاند، اما شما میتوانید آنها را بر اساس نیاز خود تغییر دهید. دقت کنید بهمنظور نمایش پیکربندی یک سرور، ما فقط تنظیمات میزبان شبکه را تنظیم میکنیم.
الاستیک سرچ به ترافیکها در پورت 9200 گوش میدهد. برای محدود کردن دسترسی و در نتیجه افزایش امنیت، خطی را که network.hostرا مشخص میکند، پیدا کرده، سپس آن را از حالت کامنت خارج کرده و مقدار آن را با localhost جایگزین کنید. در اینجا مسیر فایل etc/elasticsearch/elasticsearch.yml است:
...
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .ما localhostرا مشخص کردهایم تا Elasticsearch به تمام اینترفیسها و IPهای محدود گوش دهد. اگر میخواهید آن را تنها در یک اینترفیس خاص محدود کنید، میتوانید IP آن را به جای localhost مشخص کنید. سپس elasticsearch.yml را ذخیره کنید و ببندید. اگر از ادیتور nano استفاده میکنید، میتوانید این کار را با فشار دادن کلیدهای CTRL+X، سپس Y و درنهایت ENTER انجام دهید.
این موارد حداقل تنظیماتی هستند که میتوانید برای استفاده از الاستیک سرچ با آنها شروع کنید. اکنون میتوانید الاستیک سرچ را برای اولین بار راهاندازی کنید.
sudo systemctl start elasticsearch
در این مرحله دستور زیر را اجرا کنید تا Elasticsearch هر بار که سرور شما بوت میشود راهاندازی شود:
sudo systemctl enable elasticsearch
برای اینکه بررسی کنید که آیا سرویس Elasticsearch شما اجرا میشود یا خیر، باید درخواست HTTP را به صورت زیر ارسال کنید:
curl -X GET "localhost:9200"
اکنون پاسخی را دریافت خواهید کرد که برخی از اطلاعات اولیه را در مورد نود لوکال (local node) شما نشان میدهد:
Output
{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "n8Qu5CjWSmyIXBzRXK-j4A",
"version" : {
"number" : "7.17.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "de7261de50d90919ae53b0eff9413fd7e5307301",
"build_date" : "2022-03-28T15:12:21.446567561Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}اکنون که Elasticsearch راهاندازی شده است، بیایید Kibana، بخش بعدی Elastic Stack را نصب کنیم.
مرحله دوم: نصب و پیکربندی داشبورد Kibana
در ادامه مطلب «ELK چیست»، به نصب و پیکربندی داشبورد کیبانا میپردازیم. قبل از نصب کیبانا شما باید حتما Elasticsearch را نصب کرده باشید. انجام این کار تضمین میکند اجزایی که هر محصول به آنها وابسته است بهدرستی در جای خود قرار گرفتهاند.
از آنجایی که در مرحله قبل منبع بسته Elastic را اضافه کردهاید، میتوانید فقط اجزای باقیمانده Elastic Stack را با استفاده از apt نصب کنید:
sudo apt install kibana
سپس سرویس Kibana را فعال و راهاندازی کنید:
sudo systemctl enable kibana
sudo systemctl start kibana
از آنجایی که کیبانا به گونهای پیکربندی شده است که فقط به لوکال هاست گوش کند، باید یک پروکسی معکوس راهاندازی کنید تا اجازه دسترسی خارجی به آن را بدهید. برای این منظور از Nginx استفاده خواهیم کرد که از قبل باید روی سرور شما نصب شده باشد. پیش از این در «آموزش نصب NGINX» را تشریح کردهایم.
اکنون با استفاده از دستور openssl یک کاربر مدیریتی کیبانا بسازید تا از آن برای دسترسی به رابط وب Kibana استفاده میکنید. بهعنوانمثال، نام این حساب را kibanaadmin میگذاریم، اما برای امنیت بیشتر، به شما پیشنهاد میکنیم نامی برای کاربر خود انتخاب کنید که حدس زدن آن دشوار باشد.
استفاده از دستور زیر، کاربر و رمز عبور کیبانا را ایجاد و در فایل htpasswd.users ذخیره میکند. شما باید Nginx را طوری پیکربندی کنید که به این نام کاربری و رمز عبور نیاز داشته باشد و این فایل را لحظهای بخوانید:
echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
در این مرحله شما باید رمز عبور را وارد و آن را تأیید کنید. رمز عبور خود را در جایی ثبت کنید تا آن را فرامو ش نکنید، زیرا برای دسترسی به رابط وب کیبانا به آن نیاز خواهید داشت.
سپس یک فایل Nginx server block ایجاد کنید. بهعنوانمثال، ما فایلی به نام your_domain ایجاد میکنیم، البته سعی کنید نامی مناسب و مرتبط با فایل خود را انتخاب کنید تا در خاطرتان بماند. برای مثال، اگر یک رکورد FQDN و DNS برای این سرور تنظیم کردهاید، میتوانید فایل خود را FQDN نامگذاری کنید.
اکنون با استفاده از nano یا ویرایشگر متن دیگر، فایل بلوک سرور Nginx را ایجاد کنید:
sudo nano /etc/nginx/sites-available/your_domain
بلاک کد زیر را به فایل اضافه کنید، حتما your_domain را برای مطابقت با FQDN یا آدرس IP عمومی سرور خود بهروزرسانی کنید.
این کد، Nginx را پیکربندی میکند تا ترافیک HTTP سرور شما را به برنامه کیبانا هدایت کند که به پورت ۵۶۰۱ لوکال هست گوش میدهد. علاوه بر این، Nginx را برای خواندن فایل htpasswd.users پیکربندی میکند و نیاز به احراز هویت اولیه دارد.
به این نکته توجه ااشته باشید که ممکن است هنگام پیکربندی Nginx قبلاً این فایل را ایجاد کرده و آن را با محتوایی پر کرده باشید. در این صورت، قبل از افزودن موارد زیر، تمام محتوای موجود در فایل etc/nginx/sites-available/your_domain را حذف کنید:
در نهایت وقتی کارتان تمام شد، فایل را ذخیره کرده و آن را ببندید.
در مرحله بعد، پیکربندی جدید را با ایجاد یک پیوند نمادین به دایرکتوری فعال شده توسط سایتها فعال کنید. اگر قبلاً یک فایل بلوک سرور با همین نام در پیش نیاز Nginx ایجاد کردهاید، نیازی نیست این دستور را ایجاد کنید:
sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
سپس پیکربندی را برای خطاهای syntax بررسی کنید:
sudo nginx -t
اگر خطایی در خروجی شما گزارش شد، به مرحله قبل برگردید و دوباره بررسی کنید که آیا محتوایی را که در فایل پیکربندی خود قرار دادهاید به درستی اضافه شده است یا خیر. هنگامی که خروجی syntax is ok را مشاهده کردید ادامه دهید و سرویس Nginx را مجدداً راه اندازی کنید:
sudo systemctl reload nginx
در این مرحله شما باید فایروال UFW را فعال کنید. برای اجازه دادن اتصالات به Nginx، میتوانیم قوانین را با تایپ کردن دستور زیر تنظیم کنیم:
sudo ufw allow 'Nginx Full'
البته توجه داشته باشید که دستور بالا امکان عبور ترافیک HTTP و HTTPS از فایروال را میدهد. پیشنهاد میکنیم برای امنیت بیشتر، با استفاده از دستور زیر پروتکل HTTP را از رولها حذف نمایید تا تنها از طریق HTTPS امکان دسترسی فراهم باشد:
sudo ufw delete allow 'Nginx HTTP'
برای دسترسی به کیبانا میتوانید به آدرس http://your_domain/status مراجعه کرده و اطلاعات لاگین را وارد نمایید.
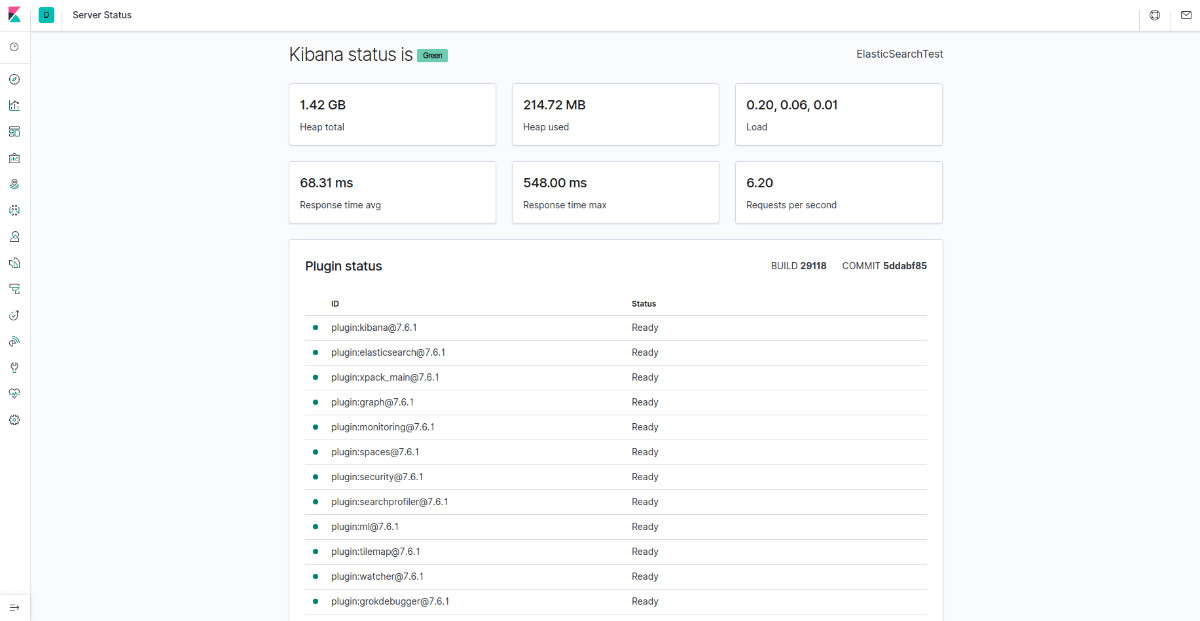
اکنون که داشبورد Kibana پیکربندی شده است، اجازه دهید مؤلفه بعدی یعنی Logstash را نصب کنیم.
بیشتر بخوانید: NGINX چیست؟
مرحله سوم: نصب و پیکربندی Logstash
اگرچه ممکن است Beats دادهها را مستقیماً به پایگاه داده Elasticsearch ارسال کند، استفاده از Logstash برای پردازش داده ها معمول است. این کار به شما امکان انعطافپذیری بیشتری را برای جمعآوری دادهها از منابع مختلف، تبدیل آن به یک فرمت معمول و ارسال آن به پایگاه داده دیگر میدهد.
Logstash را با این دستور نصب کنید:
sudo apt install logstash
پس از نصب Logstash، میتوانید به پیکربندی آن بروید. فایلهای پیکربندی Logstash در پوشه etc/logstash/conf.d/ قرار دارند. برای اطلاعات بیشتر در مورد سینتکسهای پیکربندی میتوانید به رفرنس پیکربندی که الاستیک سرچ فراهم کرده مراجعه نمایید. همانطور که فایل را پیکربندی میکنید، مفید است که Logstash را بهعنوان خط لولهای در نظر بگیرید که دادهها را در یک انتها میگیرد، آنها را به روشی پردازش میکند و به مقصد (Elasticsearch) میفرستد.
یک خط لوله Logstash دارای دو عنصر ضروری یعنی input و output و یک عنصر اختیاری یعنی filter است. پلاگینهای ورودی دادهها را از یک منبع مصرف میکنند، پلاگینهای فیلتر دادهها را پردازش میکنند و افزونههای خروجی دادهها را در مقصد مینویسد.
یک فایل پیکربندی ایجاد کنید که در آن ورودی Filebeat خود را تنظیم نمایید:
sudo nano /etc/logstash/conf.d/02-beats-input.conf
در فایل etc/logstash/conf.d/02-beats-input.conf/ پیکربندی ورودی زیر را وارد کنید. این یک ورودی beats را مشخص مینماید که به پورت TCP ۵۰۴۴ گوش میکند.
input {
beats {
port => 5044
}
}اکنون فایل را ذخیره کنید و آن را ببندید. سپس یک فایل پیکربندی ایجاد کنید:
sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
پیکربندی خروجی زیر را در فایل etc/logstash/conf.d/30-elasticsearch-output.conf/ وارد کنید. اساساً، این خروجی Logstash را پیکربندی میکند تا دادههای Beats را در Elasticsearch که در localhost:9200 اجرا میشود، در فهرستی به نام Beat مورد استفاده ذخیره کند. بیت مورد استفاده در این آموزش Filebeat است:
فایل را ذخیره کنید و آن را ببندید.
تنظیمات Logstash خود را با این دستور تست کنید:
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
اگر هیچ خطای سینتکس وجود نداشته باشد، پس از چند ثانیه خروجی Logstash نتیجه Config Validation Result: OK. Exiting Logstash را نمایش می دهد. اگر این مورد را در خروجی خود مشاهده نمیکنید، خطاهای ذکر شده در خروجی خود را بررسی کرده و پیکربندی خود را برای اصلاح آنها بهروزرسانی کنید. توجه داشته باشید که ممکن است اخطاری از OpenJDK را دریافت کنید که البته مشکلی را ایجاد نمیکند و میتوانید آن را نادیده بگیرید.
اگر تست پیکربندی شما موفقیت آمیز بود، Logstash را شروع و فعال کنید تا تغییرات پیکربندی را اعمال کند:
sudo systemctl start logstash
sudo systemctl enable logstash
اکنون Logstash به درستی اجرا میشود و بهطور کامل پیکربندی شده است.
مرحله چهارم: نصب و پیکربندی Filebeat
در ادامه مطلب «ELK چیست» به نصب و پیکربندی فایلبیت میپردازیم. الاستیک استک از چندین ارسالکننده داده سبک وزن به نام Beats برای جمعآوری دادهها از منابع مختلف و انتقال آنها به Logstash یا Elasticsearch استفاده میکند. Beatهایی که در حال حاضر از Elastic در دسترس هستند شامل:
Filebeat: فایلهای گزارش را جمعآوری و ارسال میکند.
Metricbeat: معیارها را از سیستمها و خدمات شما جمع آوری میکند.
Packetbeat: دادههای شبکه را جمعآوری و تجزیهوتحلیل میکند.
Winlogbeat: گزارش رویدادهای ویندوز را جمعآوری میکند.
Auditbeat: دادههای چارچوب ممیزی لینوکس را جمعآوری و یکپارچگی فایل را نظارت میکند.
Heartbeat: خدمات را از نظر در دسترس بودن آنها با کاوش فعال بررسی میکند.
در این آموزش ما از Filebeat برای ارسال گزارشهای محلی به Elastic Stack خود استفاده خواهیم کرد.
ابتدا Filebeat را با استفاده از apt نصب کنید:
sudo apt install filebeat
در مرحله بعد، شما باید Filebeat را برای اتصال به Logstash پیکربندی کنید. در این آموزش، فایل پیکربندی نمونهای را که همراه با Filebeat ارائه میشود، اصلاح میکنیم.
ابتدا با استفاده از دستور زیر فایل پیکربندی Filebeat را در ویرایشگر متن نانو باز کنید:
sudo nano /etc/filebeat/filebeat.yml
نکته مهم: مانند الاستیک سرچ، فایل پیکربندی Filebeat در قالب YAML است یعنی تورفتگی مناسب بسیار مهم است؛ بنابراین حتما از همان تعداد فاصلههایی که در این دستورالعملها مشخص شده است استفاده کنید.
فایل بیت از خروجیهای متعددی پشتیبانی میکند؛ اما معمولاً رویدادها را برای پردازش اضافی مستقیماً به Elasticsearch یا Logstash میفرستد. در این آموزش، ما از Logstash برای انجام پردازشهای اضافی روی دادههای جمعآوری شده توسط Filebeat استفاده میکنیم. فایل بیت نیازی به ارسال مستقیم هیچ دادهای به الاستیک سرچ ندارد، بنابراین اجازه دهید آن خروجی را غیرفعال کنیم. برای انجام این کار، بخش output.elasticsearch را پیدا کرده و خطوط زیر را با علامت # قبل از آنها را در فایل etc/filebeat/filebeat.yml/ کامنتگذاری کنید:
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...سپس قسمت output.logstash را پیکربندی کنید. خطوط :output.logstash و میزبانها: hosts: ["localhost:5044"] را با حذف # از کامنت خارج کنید. با این کار، Filebeat برای اتصال به Logstash در سرور Elastic Stack و پورت ۵۰۴۴، پورتی که قبلا یک ورودی Logstash را برای آن مشخص کرده بودیم، پیکربندی میشود. مسیر فایل مشابه قبل etc/filebeat/filebeat.yml/ است:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]اکنون فایل را ذخیره کرده و ببندید.
عملکرد فایل بیت را میتوان با ماژولهای Filebeat گسترش داد. در این آموزش ما از ماژول سیستم استفاده میکنیم که لاگهای ایجاد شده توسط سرویس ثبت سیستم توزیعهای رایج لینوکس را جمعآوری و تجزیه میکند. برای فعالسازی باید از دستور زیر استفاده کنید:
sudo filebeat modules enable system
با اجرای دستور زیر میتوانید لیستی از ماژولهای فعال و غیرفعال را مشاهده کنید:
sudo filebeat modules list
لیستی مشابه زیر را مشاهده خواهید کرد:
Output Enabled: system Disabled: apache2 auditd elasticsearch icinga iis kafka kibana logstash mongodb mysql nginx osquery postgresql redis traefik ...
بهطور پیشفرض، فایلبیت برای استفاده از مسیرهای پیشفرض، گزارشهای syslog و نیز گزارشهای مجوز پیکربندی شده است. در مورد این آموزش، نیازی نیست تنظیمات را تغییر دهید. همچنین می توانید پارامترهای ماژول را در فایل پیکربندی etc/filebeat/modules.d/system.yml/ مشاهده کنید.
در مرحله بعد، باید خطوط لوله دریافت Filebeat را راهاندازی کنیم، که دادههای گزارش را قبل از ارسال از طریق logstash به Elasticsearch، تجزیه میکنند. جهت بارگیری خط لوله ورودی برای ماژول سیستم، دستور زیر را وارد کنید:
sudo filebeat setup --pipelines --modules system
سپس، قالب ایندکس را در Elasticsearch بارگذاری کنید. فهرست الاستیک سرچ مجموعهای از اسناد است که دارای ویژگی های مشابه هستند. ایندکسها با یک نام شناسایی میشوند که برای اشاره به شاخص هنگام انجام عملیات مختلف در داخل آن استفاده میشود. هنگامی که یک فهرست جدید ایجاد شد، الگوی فهرست به طور خودکار اعمال میشود.
برای بارگذاری قالب از دستور زیر استفاده کنید:
sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
Output Index setup finished.
فایل بیت همراه با نمونه داشبورد کیبانا است که به شما امکان میدهد دادههای Filebeat را در Kibana نمایش دهید. قبل از اینکه بتوانید از داشبوردها استفاده کنید، باید الگوی فهرست راایجاد کرده و داشبوردها را در کیبانا بارگذاری کنید.
با لود شدن داشبوردها، اتصال Filebeat به Elasticsearch برقرار میشود تا اطلاعات نسخه را بررسی کند. برای بارگیری داشبوردها زمانی که Logstash فعال است، باید خروجی Logstash را غیرفعال و خروجی Elasticsearch را فعال کنید. برای انجام این کار دستور زیر را باید به کار ببرید:
sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
پس از چند دقیقه، باید خروجی مشابه زیر دریافت کنید:
Output
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelinesاکنون میتوانید Filebeat را شروع و فعال کنید:
sudo systemctl start filebeat
sudo systemctl enable filebeat
اگر Elastic Stack خود را بهدرستی تنظیم کرده باشید، Filebeat شروع به ارسال گزارشهای syslog و مجوز به Logstash کرده و سپس دادهها را در Elasticsearch بارگیری میکند.
برای اینکه مطمئن شوید الاستیک سرچ واقعاً این دادهها را دریافت میکند، فهرست Filebeat را با این دستور جستجو کنید:
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
اکنون شما باید خروجی زیر را دریافت کنید:
. . .
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.17.2-2022.04.18",
"_type" : "_doc",
"_id" : "YhwePoAB2RlwU5YB6yfP",
"_score" : 1.0,
"_source" : {
"cloud" : {
"instance" : {
"id" : "294355569"
},
"provider" : "digitalocean",
"service" : {
"name" : "Droplets"
},
"region" : "tor1"
},
"@timestamp" : "2022-04-17T04:42:06.000Z",
"agent" : {
"hostname" : "elasticsearch",
"name" : "elasticsearch",
"id" : "b47ca399-e6ed-40fb-ae81-a2f2d36461e6",
"ephemeral_id" : "af206986-f3e3-4b65-b058-7455434f0cac",
"type" : "filebeat",
"version" : "7.17.2"
},
. . .اگر خروجی شما 0 بازدید کل را نشان میدهد، Elasticsearch هیچ گزارشی را در فهرستی که جستجو کردهاید، دریافت نمیکند و باید تنظیمات خود را از نظر خطا بررسی کنید. در صورتی که خروجی مشکلی نداشت، میتوانید از طریق FQDN یا آدرس IP و از طریق مرورگر به داشبورد کیبانا وارد شوید.
جمعبندی
در این مطلب، به طور کامل دیدیم که ELK چیست و چرا استفاده از آن اهمیت دارد. ELK با آمار میلیونی دانلود برای مؤلفههای خود، به عنوان یکی از محبوبترین پلتفرمهای مدیریت گزارشهای سرور و سیستمها در جهان شناخته میشود. این پلتفرم از اجزای مختلف تشکیل شده که هریک وظایف خاص خود را داشته و در کنار هم با ادغام عملکردهای مختلف، روند مدیریت دادهها و گزارشها را سادهتر میکنند.
ابر زَس تحت «سرویس مدیریت شده» ELK را روی سرور ابری یا دیتاسنتر ابری شما نصب کرده و در اختیارتان قرار میدهد.